

【香港商报网讯】记者黄裕勇报道:8月29日,2019世界人工智能大会(WAIC)于上海世博中心拉开帷幕,海内外大咖齐聚,学术界工业界交汇,共话人工智能未来。微众银阿行首席人工智能官杨强教授在大会主论坛——“科学前沿”演讲时表示,联邦学习已经成为AI在学术界和工业界的新趋势,未来行业面临的社会大众的要求和监管会越来越严格,联邦学习能够在满足用户隐私保护和数据安全需求的同时,实现多方共赢。
微众银行作为联邦学习的国内首倡者和领导者,在杨强教授的带领下首次提出了“联邦迁移学习”,并通过领衔联邦学习国际标准(IEEE标准)制定、开源自研联邦学习框架Federated AI Technology Enabler(简称FATE)等来推动联邦学习技术在行业中的落地。
杨强教授在演讲中介绍说,微众银行负责人工智能的工作,接触到很多人工智能的应用场景。作为一家互联网银行,微众银行服务的用户数已经超过了1.7亿,提供服务主要借助的手段就是人工智能和机器人。在服务过程中有很多环节,比方说业务咨询、审核批准贷款文件、对申请人进行人脸识别、语音识别等身份核验、客服问答等。在金融领域,不仅要建立用户画像和模型找到用户,更要建立一整条长链路来服务广大的用户。
“这些应用都离不开一个元素——数据,尤其是大数据”。杨强认为,在这种情况下,数据聚合的需求十分强烈,却很难得到满足。其中有一个很重要的原因是社会对于用户隐私的要求越来越高。“我们一方面面临数据割裂,没有大数据来训练人工智能;另一方面,法律法规和社会对安全的严格要求又限制了数据的融合。大数据变成了人工智能的挑战。”
为积极地寻找一些新的技术方向来解决数据挑战,微众银行的方法和方向叫做“联邦学习”,英文叫“Federated Learning”。数据的各个拥有方,在各自数据不出本地的情况下建立模型,并且让这个模型能够共享,那么在建立模型的过程中便不会侵犯用户的隐私,整个建模的过程就叫联邦学习的框架和算法。
这样的模型不仅需要一个机器学习算法,更需要一个分布式的机器学习算法,针对两个数据集既不重叠用户特征,又不重叠用户的场景下,微众银行提出一个新的算法,叫做联邦迁移学习。它可以利用迁移学习的算法,把这两方数据模型的本质挖掘出来,把抽象的模型加以聚合,在聚合的过程中保护用户隐私,也取得非常大的成功。
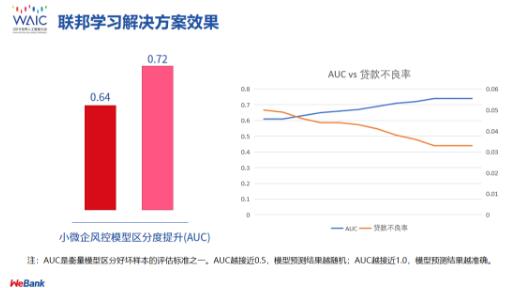
虽然联邦学习的框架最近才提出来,但是它在产业界的应用已经有成熟的进展。比方说我们最近在一个金融信贷的场景下就取得了非常成功的应用:一方是互联网企业,有很多用户的行为数据;另一方是金融企业——银行,需要建立一个更准确的用户信贷模型。这时利用纵向联邦学习,把两边的模型加以共享,进行更新,这样模型就能够更有利,随着数据量的增加,效果也大为增加。以下是效果图。
同时,我们也尝试了很多不同的应用场景,比方说在城市管理领域,利用散落在各地的割裂的计算机视觉数据来建立一个安全、共享的模型;在语音识别领域,不同的机构有不同的语音数据,不同的服务中心,它们也可以建立一个联邦学习来解决用户隐私的问题。
杨强表示,“机器学习离不开大数据,大数据离不开安全和保护隐私的考虑,联邦学习是一个既能建立大数据模型,又能保护数据安全和用户隐私的有利的工具”。他希望更多的人能加入一起建立联邦学习生态。


