






六月最後一天,中國AI大模型天團再次迎來一位重量級選手—美團。
據悉,LongCat-2.0採用MoE架構,總參數規模1.6萬億,每個Token激活參數約480億,原生支持1M超長上下文,可一次處理百萬字級輸入。模型深度適配 Claude Code、OpenClaw、Hermes 等主流 Harness,在Coding任務上有很強的表現。
OpenRouter總調用量躋身全球前三,性能接近Claude Opus 4.6
今年4月底,美團曾發布LongCat-2.0-Preview版本,並以匿名的方式,接入全球最大的大模型 API 路由平台OpenRouter。
OpenRouter數據顯示,截至6月底,LongCat-2.0-Preview的總調用量已躋身全球前三。
在Hermes、Claude Code、OpenClaw等Agent場景下,LongCat-2.0-Preview的月調用量分列全球第一、第二和第三位。其在Claude Code的月調用量,僅次於Claude Opus 4.8,是最受全球開發者歡迎的免費模型之一。
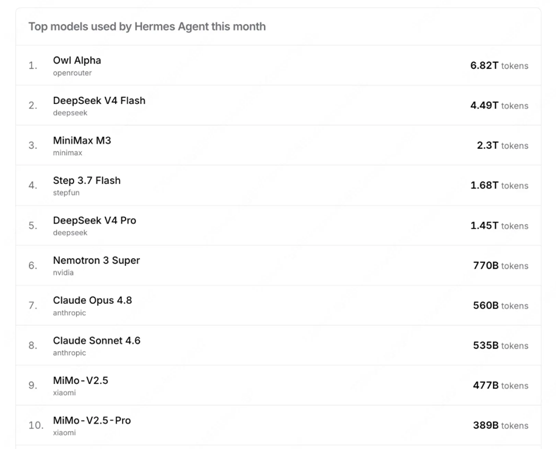
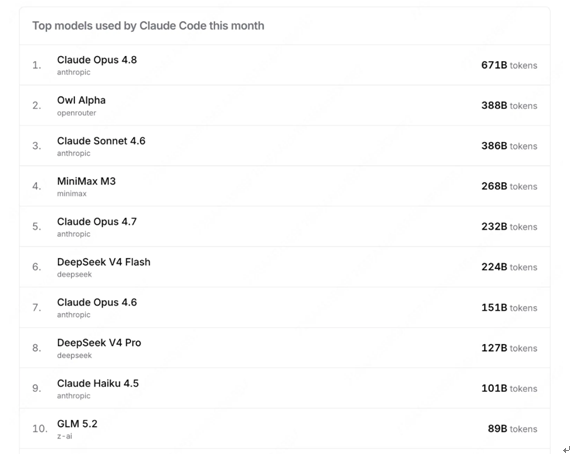
OpenRouter數據顯示,匿名為Owl Alpha的LongCat-2.0測試版本,在Hermes月調用量位列全球第一、Claude Code的月調用量位列全球第二。
社區反饋顯示,在工具調用、複雜指令執行等 Agent 核心能力方面,LongCat-2.0-Preview接近Claude Opus 4.6,落後於最新的Claude Opus 4.8。在國產大模型中,LongCat-2.0-Preview位列頂尖梯隊。
相關技術報告顯示,LongCat-2.0引入ScMoE跨層快捷連接架構、零計算專家機制、Ngram Embedding增強等多項原創設計。其中,零計算專家機制可實現Token級動態計算預算,讓複雜Token激活更多專家,簡單Token節省算力,該機制為業界首創。
訓練、推理全程依靠國產算力,將於近期開源核心技術
作為首個「全國產」萬億參數大模型,LongCat-2.0全程在國產算力上完成訓練,峰值規模超過5萬張國產算力卡,是迄今為止國產算力上完成的最大訓練任務。
據悉,2023年起,美團就與國產算力廠商共同推進「模芯協同」研發,從早期的小規模驗證到超大規模穩定訓練,逐步攻克了萬卡級容錯恢復、NPU確定性計算、算力利用率提升等核心難題,驗證了大規模國產訓練的可行性。
LongCat-2.0的實踐表明,目前國產算力卡雖然落後於全球頂尖水平,但計算正確性和精度已足夠滿足需求,甚至局部略優,已經可以支撐前沿模型的全流程訓練。對於激活存量國產芯片而言,這是一個重要突破。
據悉,由於算力優化、技術突破等綜合因素,LongCat-2.0的訓練、推理成本消耗,低於全球其他萬億參數級別的大模型。
對此,LongCat官方宣布,將於近期在多平台同步開源Infra 框架、推理引擎、模型參數等核心技術,以回饋全球開發者社區。(記者林彬彬)





電話:(香港)852-2564 0768
(深圳)86-755-83518792 83518734 83518291
地址:香港九龍觀塘道332號香港商報大廈









